🟢 Cadena de pensamiento
El Encadenamiento de pensamiento (CoT, por sus siglas en inglés "Chain of Thought")1 es un método de indicaciones que se desarrolló recientemente y que alienta al LLM a explicar su razonamiento. La imagen a continuación1 muestra una indicación estándar de "pocos ejemplos" (izquierda) en comparación con una indicación de encadenamiento de pensamiento (derecha).
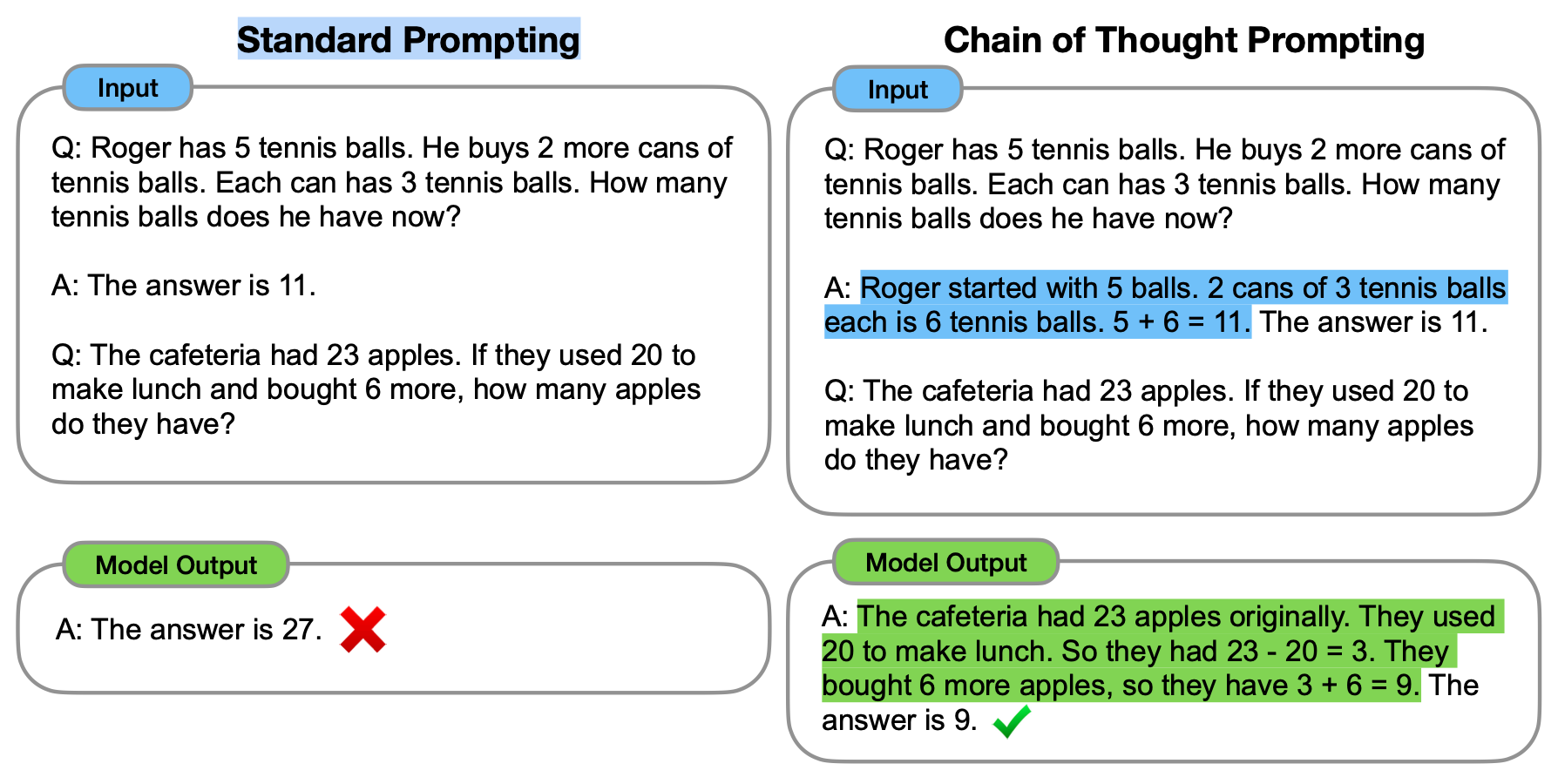
La idea principal de CoT es que, al mostrarle al LLM algunos %%ejemplos|ejemplos%% con pocos disparos en los que se explica el proceso de razonamiento, el LLM también mostrará el proceso de razonamiento al responder la indicación. Esta explicación del razonamiento a menudo conduce a resultados más precisos.
Ejemplo
Aquí hay algunas demostraciones. La primera muestra que GPT-3 (davinci-003) no puede resolver un problema de palabras simple. La segunda muestra que GPT-3 (davinci-003) resuelve con éxito el mismo problema utilizando la indicación de CoT.
Incorrecto
Correcto
Resultados
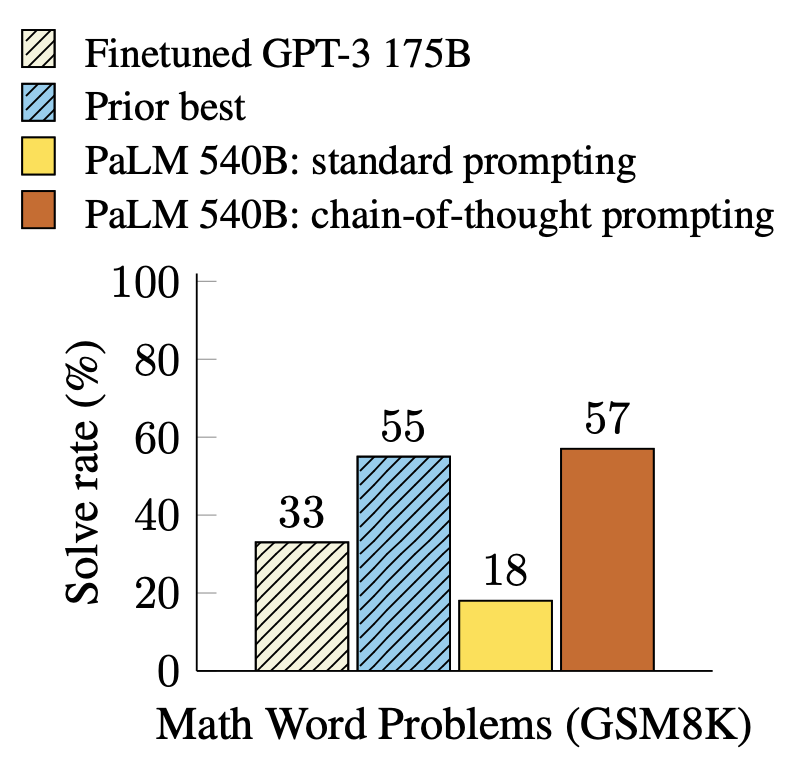
Se ha demostrado que CoT es efectivo para mejorar los resultados en tareas como aritmética, sentido común y tareas de razonamiento simbólico1. En particular, prompted PaLM 540B2 alcanza una precisión de tasa de resolución del 57% en GSM8K3 (SOTA en ese momento).
Limitaciones
Es importante destacar que, según Wei et al., "CoT solo produce mejoras en el rendimiento cuando se utiliza con modelos de ∼100B de parámetros". Modelos más pequeños escribieron cadenas de pensamiento ilógicas, lo que llevó a una precisión peor que la de la prueba estándar. Los modelos suelen obtener mejoras de rendimiento a partir de la sugerencia CoT de manera proporcional al tamaño del modelo.
Notas
Ningún modelo de lenguaje fue dañado afinado en el proceso de escritura de este capítulo 😊.
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., & Zhou, D. (2022). Chain of Thought Prompting Elicits Reasoning in Large Language Models. ↩
- Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., Chung, H. W., Sutton, C., Gehrmann, S., Schuh, P., Shi, K., Tsvyashchenko, S., Maynez, J., Rao, A., Barnes, P., Tay, Y., Shazeer, N., Prabhakaran, V., … Fiedel, N. (2022). PaLM: Scaling Language Modeling with Pathways. ↩
- Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., & Schulman, J. (2021). Training Verifiers to Solve Math Word Problems. ↩